This article tries to minimize hard-coding in ETL, thereby increasing flexibility, reusability, readabilty and avoides rework through the judicious use of Informatica Parameters and Variables.
Step by step we will see what all attributes can be parameterized in Informatica from Mapping level to the Session, Worklet, Workflow, Folder and Integration Service level.
Parameter files provide us with the flexibility to change parameter and variable values every time we run a session or workflow. |
So, let us begin the journey!
Parameter File in Informatica
- A parameter file contains a list of parameters and variables with their assigned values.
- $$LOAD_SRC=SAP
- $$DOJ=01/01/2011 00:00:01
- $PMSuccessEmailUser=admin@mycompany.com
- Each heading section identifies the Integration Service, Folder, Workflow, Worklet, or Session to which the parameters or variables apply.
- [Global]
- [Folder_Name.WF:Workflow_Name.WT:Worklet_Name.ST:Session_Name]
- [Session_Name]
- Define each parameters and variables definition in the form name=value pair on a new line directly below the heading section. The order of the parameters and variables is not important within the section.
[Folder_Name.WF:Workflow_Name.ST:Session_Name] $DBConnection_SRC=Info_Src_Conn $DBConnection_TGT=Info_Tgt_Conn $$LOAD_CTRY=IND $Param_Src_Ownername=ODS $Param_Src_Tablename=EMPLOYEE_IND
- The Integration Service interprets all characters between the beginning of the line and the first equal signs as the parameter name and all characters between the first equals sign and the end of the line as the parameter value. If we leave a space between the parameter name and the equals sign, Integration Service interprets the space as a part of the parameter name.
- If a line contains multiple equal signs, Integration Service interprets all equals signs after the first one as part of the parameter value.
- Do not enclose parameter or variable values in quotes as Integration Service interprets everything after the first equals sign as part of the value.
- Do not leave unnecessary line breaks or spaces as Integration Service interprets additional spaces as part of a parameter name or value.
- Mapping parameter and variable names are not case sensitive.
- To assign a null value, set the parameter or variable value to <null> or simply leave the value blank.
- $PMBadFileDir=<null>
- $PMCacheDir=
- The Integration Service ignores lines that are not valid headings,or do not contain an equals sign character (=) as Comments.
--------------------------------------- Created on 01/01/2011 by Admin. Folder: Work_Folder CTRY:SG ; Above are all valid comments ; because this line contains no equals sign.
- Precede parameters and variables used within mapplets with their corresponding mapplet name.
[Session_Name] mapplet_name.LOAD_CTRY=SG mapplet_name.REC_TYPE=D
- If a parameter or variable is defined in multiple sections in the parameter file, the parameter or variable with the smallest scope takes precedence over parameters or variables with larger scope.
[Folder_Name.WF:Workflow_Name] $DBConnection_TGT=Orcl_Global [Folder_Name.WF:Workflow_Name.ST:Session_Name] $DBConnection_TGT=Orcl_SG
In the specified session name, the value for session parameter $DBConnection_TGT is Orcl_SG and for rest all other sessions in the workflow, the connection object used will be Orcl_Global.
Scope of Informatica Parameter File
Next we take a quick look on how we can restrict the scope of Parameters by changing the Parameter File Heading section.
- [Global] -> All Integration Services, Workflows, Worklets, Sessions.
- [Service:IntegrationService_Name] -> The Named Integration Service and Workflows, Worklets, Sessions that runs under this IS.
- [Service:IntegrationService_Name.ND:Node_Name]
- [Folder_Name.WF:Workflow_Name] -> The Named workflow and all sessions within the workflow.
- [Folder_Name.WF:Workflow_Name.WT:Worklet_Name] -> The Named worklet and all sessions within the worklet.
- [Folder_Name.WF:Workflow_Name.WT:Worklet_Name.WT:Nested_Worklet_Name] -> The Named nested worklet and all sessions within the nested worklet.
- [Folder_Name.WF:Workflow_Name.WT:Worklet_Name.ST:Session_Name] -> The Named Session.
- [Folder_Name.WF:Workflow_Name.ST:Session_Name] -> The Named Session.
- [Folder_Name.ST:Session_Name] -> The Named Session.
- [Session_Name] -> The Named Session.
Types of Parameters and Variables
There are many types of Parameters and Variables we can define. Please find below the comprehensive list:
- Service Variables: To override the Integration Service variables such as email addresses, log file counts, and error thresholds. Examples of service variables are $PMSuccessEmailUser, $PMFailureEmailUser, $PMWorkflowLogCount, $PMSessionLogCount, and $PMSessionErrorThreshold.
- Service Process Variables: To override the the directories for Integration Service files for each Integration Service process. Examples of service process variables are $PMRootDir, $PMSessionLogDir and $PMBadFileDir.
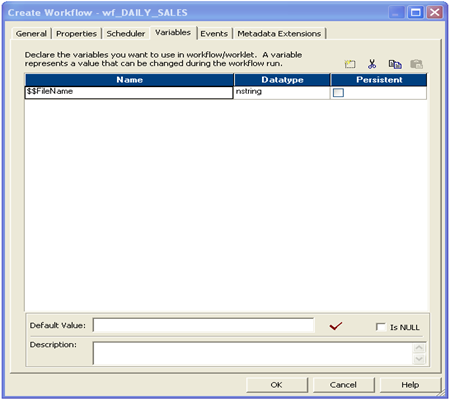
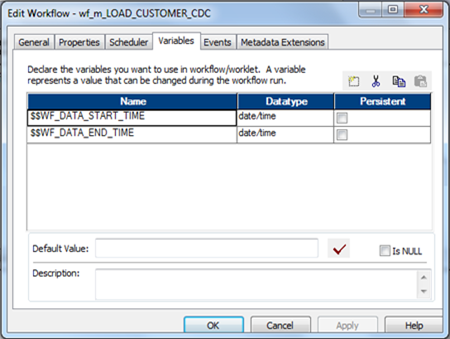
- Workflow Variables: To use any variable values at workflow level. User-defined workflow variables like $$Rec_Cnt
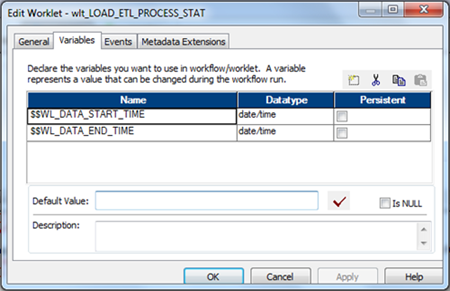
- Worklet Variables: To use any variable values at worklet level. User-defined worklet variables like $$Rec_Cnt. We can use predefined worklet variables like $TaskName.PrevTaskStatus in a parent workflow, but we cannot use workflow variables from the parent workflow in a worklet.
- Session Parameters: Define values that may change from session to session, such as database connections, db owner, or file names. $PMSessionLogFile, $DynamicPartitionCount and $Param_Tgt_Tablename are user-defined session parameters. List of other built in Session Parameters:$PMFolderName, $PMIntegrationServiceName, $PMMappingName, $PMRepositoryServiceName, $PMRepositoryUserName, $PMSessionName, PMSessionRunMode [Normal/Recovery], $PM_SQ_EMP@numAffectedRows, $PM_SQ_EMP@numAppliedRows, $PM_SQ_EMP@numRejectedRows, $PM_SQ_EMP@TableName, $PM_TGT_EMP@numAffectedRows, $PM_TGT_EMP@numAppliedRows, $PM_TGT_EMP@numRejectedRows, $PM_TGT_EMP@TableName, $PMWorkflowName, $PMWorkflowRunId, $PMWorkflowRunInstanceName.Note: Here SQ_EMP is the Source Qualifier Name and TGT_EMP is the Target Definition.
- Mapping Parameters: Define values that remain constant throughout a session run. Examples are $$LOAD_SRC, $$LOAD_DT. Predefined parameters examples are $$PushdownConfig.
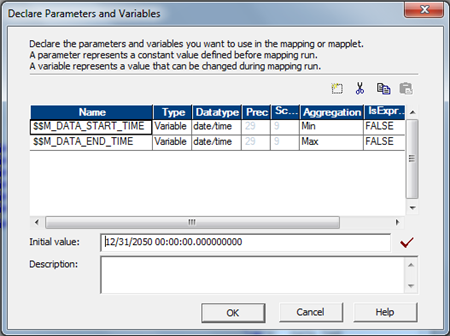
- Mapping Variables: Define values that changes during a session run. The Integration Service saves the value of a mapping variable to the repository at the end of each successful session run and uses that value the next time you run the session. Example $$MAX_LOAD_DT
Difference between Mapping Parameters and Variables
A mapping parameter represents a constant value that we can define before running a session. A mapping parameter retains the same value throughout the entire session. If we want to change the value of a mapping parameter between session runs we need to Update the parameter file.
A mapping variable represents a value that can change through the session. The Integration Service saves the value of a mapping variable to the repository at the end of each successful session run and uses that value the next time when we run the session. Variable functions like SetMaxVariable, SetMinVariable, SetVariable, SetCountVariable are used in the mapping to change the value of the variable. At the beginning of a session, the Integration Service evaluates references to a variable to determine the start value. At the end of a successful session, the Integration Service saves the final value of the variable to the repository. The next time we run the session, the Integration Service evaluates references to the variable to the saved value. To override the saved value, define the start value of the variable in the parameter file.
Parameterize Connection Object
First of all the most common thing we usually Parameterise is the Relational Connection Objects. Since starting from Development to Production environment the connection information obviously gets changed. Hence we prefer to go with parameterisation rather than to set the connection objects for each and every source, target and lookup every time we migrate our code to new environment.E.g.
- $DBConnection_SRC
- $DBConnection_TGT
If we have one source and one target connection objects in your mapping, better we relate all the Sources, Targets, Lookups and Stored Procedures with $Source and $Target connection. Next we only parameterize $Source and $Target connection information as:
- $Source connection value with the Parameterised Connection $DBConnection_SRC
- $Target connection value with the Parameterised Connection $DBConnection_TGT
Lets have a look how the Parameter file looks like. Parameterization can be done at folder level, workflow level, worklet level and till session level.
[WorkFolder.WF:wf_Parameterize_Src.ST:s_m_Parameterize_Src] $DBConnection_SRC=Info_Src_Conn $DBConnection_TGT=Info_Tgt_Conn

Here Info_Src_Conn, Info_Tgt_Conn are Informatica Relational Connection Objects.
Note: $DBConnection lets Informatica know that we are Parameterizing Relational Connection Objects.
For Application Connections use $AppConnection_Siebel, $LoaderConnection_Orcl when parameterizing Loader Connection Objects and $QueueConnection_portal for Queue Connection Objects.
In a precise manner we can use Mapping level Parameter and Variables as and when required. For example $$LOAD_SRC, $$LOAD_CTRY, $$COMISSION, $$DEFAULT_DATE, $$CDC_DT.
Parameterize Source Target Table and Owner Name
Situation may arrive when we need to use a single mapping from various different DB Schema and Table and load the data to different DB Schema and Table. Condition provided the table structure is the same.
A practical scenario may be we need to load employee information of IND, SGP and AUS and load into global datawarehouse. The source tables may be orcl_ind.emp, orcl_sgp.employee, orcl_aus.emp_aus.
So we can fully parameterise the Source and Target table name and owner name.
- $Param_Src_Tablename
- $Param_Src_Ownername
- $Param_Tgt_Tablename
- $Param_Tgt_Ownername
The Parameterfile:-
[WorkFolder.WF:wf_Parameterize_Src.ST:s_m_Parameterize_Src] $DBConnection_SRC=Info_Src_Conn $DBConnection_TGT=Info_Tgt_Conn $Param_Src_Ownername=ODS $Param_Src_Tablename=EMPLOYEE_IND $Param_Tgt_Ownername=DWH $Param_Tgt_Tablename=EMPLOYEE_GLOBAL
Check the implementation image below:


Parameterize Source Qualifier Attributes
Next comes what are the other attributes we can parameterize in Source Qualifier.
- Sql Query: $Param_SQL
- Source Filter: $Param_Filter
- Pre SQL: $Param_Src_Presql
- Post SQL: $Param_Src_Postsql
If we have user-defined SQL statement having join as well as filter condition, its better to add a$$WHERE clause at the end of your SQL query. Here the $$WHERE is just a Mapping level Parameter you define in your parameter file.
In general $$WHERE will be blank. Suppose we want to run the mapping for todays date or some other filter criteria, what you need to do is just to change the value of $$WHERE in Parameter file.
$$WHERE=AND LAST_UPDATED_DATE > SYSDATE -1 [WHERE clause already in override query] OR $$WHERE=WHERE LAST_UPDATED_DATE > SYSDATE -1 [NO WHERE clause in override query]
Parameterize Target Definition Attributes
Next what are the other attributes we can parameterize in Target Definition.
- Update Override: $Param_UpdOverride
- Pre SQL: $Param_Tgt_Presql
- Post SQL: $Param_Tgt_Postsql
$Param_UpdOverride=UPDATE $$Target_Tablename.EMPLOYEE_G SET ENAME = :TU.ENAME, JOB = :TU.JOB, MGR = :TU.MGR, HIREDATE = :TU.HIREDATE, SAL = :TU.SAL, COMM = :TU.COMM, DEPTNO = :TU.DEPTNO WHERE EMPNO = :TU.EMPNO
Parameterize Flatfile Attributes
Now lets see what we can do when it comes to Source, Target or Lookup Flatfiles.
- Source file directory: $PMSourceFileDir\ [Default location SrcFiles]
- Source filename: $InputFile_EMP
- Source Code Page: $Param_Src_CodePage
- Target file directory: $$PMTargetFileDir\ [Default location TgtFiles]
- Target filename: $OutputFile_EMP
- Reject file directory: $PMBadFileDir\ [Default location BadFiles]
- Reject file: $BadFile_EMP
- Target Code Page: $Param_Tgt_CodePage
- Header Command: $Param_headerCmd
- Footer Command: $Param_footerCmd
- Lookup Flatfile: $LookupFile_DEPT
- Lookup Cache file Prefix: $Param_CacheName
Parameterize FTP Connection Object Attributes
Now for FTP connection objects following are the attributes we can parameterize:
- FTP Connection Name: $FTPConnection_SGUX
- Remote Filename: $Param_FTPConnection_SGUX_Remote_Filename [Use the directory path and filename if directory is differnt than default directory]
- Is Staged: $Param_FTPConnection_SGUX_Is_Staged
- Is Transfer Mode ASCII:$Param_FTPConnection_SGUX_Is_Transfer_Mode_ASCII
Parameterization of Username and password information of connection objects are possible with$Param_OrclUname.
When it comes to password its recommended to Encrypt the password in the parameter file using the pmpasswd command line program with the CRYPT_DATA encryption type.
Using Parameter File
We can specify the parameter file name and directory in the workflow or session properties or in the pmcmd command line.
We can use parameter files with the pmcmd startworkflow or starttask commands. These commands allows us to specify the parameter file to use when we start a workflow or session.
The pmcmd -paramfile option defines which parameter file to use when a session or workflow runs. The -localparamfile option defines a parameter file on a local machine that we can reference when we do not have access to parameter files on the Integration Service machine
The following command starts workflow using the parameter file, param.txt:
pmcmd startworkflow -u USERNAME -p PASSWORD -sv INTEGRATIONSERVICENAME -d DOMAINNAME -f FOLDER -paramfile 'infa_shared/BWParam/param.txt' WORKFLOWNAME
The following command starts taskA using the parameter file, param.txt:
pmcmd starttask -u USERNAME -p PASSWORD -sv INTEGRATIONSERVICENAME -d DOMAINNAME -f FOLDER -w WORKFLOWNAME -paramfile 'infa_shared/BWParam/param.txt' SESSION_NAME
Workflow and Session Level Parameter File
When we define a workflow parameter file and a session parameter file for a session within the workflow, the Integration Service uses the workflow parameter file, and ignores the session parameter file. What if we want to read some parameters from Parameter file at Workflow level and some defined at Session Level parameter file.
The solution is simple:
- Define Workflow Parameter file. Say infa_shared/BWParam/param_global.txt
- Define Workflow Variable and assign its value in param_global.txt with the session level param file name. Say $$var_param_file=/infa_shared/BWParam/param_runtime.txt
- In the session properties for the session, set the parameter file name to this workflow variable.
- Add $PMMergeSessParamFile=TRUE in the Workflow level Parameter file.
Content of infa_shared/BWParam/param_global.txt
[WorkFolder.WF:wf_runtime_param] $DBConnection_SRC=Info_Src_Conn $DBConnection_TGT=Info_Tgt_Conn $PMMergeSessParamFile=TRUE $$var_param_file=infa_shared/BWParam/param_runtime.txt
Content of infa_shared/BWParam/param_runtime.txt
[WorkFolder.wf:wf_runtime_param.ST:s_m_emp_cdc] $$start_date=2010-11-02 $$end_date=2010-12-08
The $PMMergeSessParamFile property causes the Integration Service to read both the session and workflow parameter files.